![]()
 Star
Star
As part of the code review process on GitHub, developers can leave comments on portions of the unified diff of a GitHub pull request. These comments are extremely valuable in facilitating technical discussion amongst developers, and in allowing developers to get feedback on their code submissions.
But what do code reviewers usually discuss in these comments?
In an effort to better understand code reviewing discussions, we’re going to create an SVM classifier to classify over 30 000 GitHub review comments based on the main code-related topic addressed by each comment (e.g. naming, readability, etc.).
Grab the Jupyter Notebook for this experiment on GitHub.

- Review Comment Classifications
- Loading The Data Set
- Preprocessing The Data
- Extracting Features
- Training The Classifier
- Classifying GitHub Review Comments
- Discussion
- Closing
Review Comment Classifications
The list of classifications we’re going to incorporate into our classifier are summarized in the table below. This list was developed based on a manual survey of approximately 2000 GitHub review comments I performed on randomly selected, but highly forked Java repositories on GitHub.
The selected categories reflect the most frequently occurring topics encountered in the surveyed review comments. Majority of the categories are related to code level concepts (e.g. variable naming, exception handling); however, certain review comments that did not naturally fall into any existing categories and were unrelated to the overall goal of code reviewing were placed in the “other” category.
In situations where a review comment discussed more than one subject, I gave it a classification according to the topic it spent the most words discussing.
| Category | Label | Further Explanation | Sample Comment |
|---|---|---|---|
| Readability | 1 | Comments related to readability, style, general project conventions. | “This code looks very convoluted to me” |
| Naming | 2 | “I think foo would be a more appropriate name” | |
| Documentation | 3 | Comments related to licenses, package info, module documentation, commenting. | “Please add a comment here explaining this logic” |
| Error/Resource Handling | 4 | Comments related to exception/resource handling, program failure, termination analysis, resource . | “Forgot to catch a possible exception here” |
| Control Structures/Program Flow | 5 | Comments related to usage of loops, if-statements, placement of individual lines of code. | “This if-statement should be moved after the while loop” |
| Visibility/ Access | 6 | Comments related to access level for classes, fields, methods and local variables. | “Make this final” |
| Efficiency / Optimization | 7 | “Many unnecessary calls to foo() here” | |
| Code Organization/ Refactoring | 8 | Comments related to extracting code from methods and classes, moving large chunks of code around. | “Please extract this logic into a separate method” |
| Concurrency | 9 | Comments related to threads, synchronization, parallelism. | “This class does not look thread safe” |
| High Level Method Semantics & Design | 10 | Comments relating to method design and semantics. | “This method should return a String” |
| High Level Class Semantics & Design | 11 | Comments relating to class design and semantics. | “This should extend Foo” |
| Testing | 12 | “is there a test for this?” | |
| Other | 13 | Comments not relating to categories 1-12. | “Looks good”, “done”, “thanks” |
Loading The Data Set
Now we’ll discuss our SVM text classifier implementation. This experiment represents a typical supervised learning classification exercise.
We’ll start by first loading our training data consisting of two files representing 2000 manually labeled comment-classification pairs. The first file contains a review comment on each line, while the second file contains manually determined classifications for each corresponding review comment on each line.
with open('review_comments.txt') as f:
review_comments = f.readlines()
with open('review_comments_labels.txt') as g:
classifications = g.readlines()
Preprocessing The Data
Next, we are going to preprocess the raw data in multiple steps to prepare it for use by our SVM classifier. First, we remove all formatting characters from each comment that are associated with the Markdown syntax. This step is important because the additional formatting related characters introduced by the Markdown standard will negatively impact our classifier’s ability to recognize identical words.
import re
def formatComment(comment):
comment = re.sub("\*|\[|\]|#|\!|,|\.|\"|;|\?|\(|\)|`.*?`", "", comment)
comment = re.sub("\.|\(|\)|<|>", " ", comment)
comment = ' '.join(comment.split())
return comment
def formatComments(comments):
for index, comment in enumerate(comments):
comments[index] = formatComment(comment)
formatComments(review_comments)
A note on using stopwords and stemmers. My experimental results showed that using off the shelf stopword lists and stemmers to preprocess the data slightly decreased the accuracy of the final classifier. This is why I have not used any of these techniques in this experiment.
Extracting Features
The next step of our preprocessing stage is to convert the comment reviews into numerical feature vectors. This will represent the review comments in a way that will allow them to be processed by our machine learning algorithms. To do this, we will use the bag of words method, which
represents a sentence using a feature vector developed based on the number of occurrences of each
term, known as term frequency. We’ll use the Scikit-learn Python library to create feature vectors for our
review comments using the CountVectorizer module.
# Extracting features from text files
from sklearn.feature_extraction.text import CountVectorizer
count_vect = CountVectorizer()
comments_train_counts = count_vect.fit_transform(review_comments)
comments_train_counts.shape
(1036, 2787)
We wil also experiment with incorporating the inverse document frequency statistic, a common technique used in text classification experiments. To understand how the technique works, consider a commonly occurring term like “the”. A simple bag of words model based only on term frequency would tend to incorrectly emphasize review comments which happen to use the word “the” more frequently, without giving enough weight to the more meaningful terms like “variable” and “naming”. This is problematic as the term “the” is not a good keyword to distinguish relevant and non-relevant documents and terms, unlike the less-common words “variable” and “naming”. Hence the inverse document frequency factor is incorporated which diminishes the weight of terms that occur very frequently in the document set and increases the weight of terms that occur rarely.
Putting it all together, the weight the td-idf statistic assigns to a given term is:
- Highest when the term occurs many times within a small number of review comments
- Lower when the term occurs fewer times in a review comment, or occurs in many review comments
- Lowest when the term occurs in virtually all review comments.
At this point, we can view each review comment as a vector with one component corresponding to each term in the dictionary, together with a weight for each component that is given by the tf-idf statistic. For dictionary terms that do not occur in a document, this weight is zero. This vector form will prove to be crucial to the scoring and ranking capabilities of our SVM classifier.
# TF-IDF
from sklearn.feature_extraction.text import TfidfTransformer
tfidf_transformer = TfidfTransformer()
comments_train_tfidf = tfidf_transformer.fit_transform(comments_train_counts)
comments_train_tfidf.shape
(1036, 2787)
Now that the classifier itself is almost ready, an important consideration now is the amount of training data to use for testing the classifier.
After ensuring that at least 100 review comments for most of the classification are present in our labeled data set, I experimented with different numbers of review comments to see what gave the best results. 2000 review comments seemed to give a good enough accuracy for our purposes. We will therefore dedicate 80% of our 2000 GitHub review comments data to the training set, which we will use to train our SVM classifier. The remaining 20% of the data will be dedicated to the test set, which we will use to test the performance of the developed classifier.
from sklearn.model_selection import train_test_split
comment_train, comment_test, classification_train, classification_test = train_test_split(review_comments, classifications, test_size=0.2)
Training The Classifier
Lastly, we can complete our classifier by combining the components developed so far with the scikit SVM classifier using the scikit Pipeline module. The purpose of the pipeline is to assemble several steps that can be cross-validated together while setting different parameters. We also use the scikit SGDClassifier module to train our SVM model using Stochastic Gradient Descent (SGD). SGD is an iterative based optimization technique. In this case, the technique modifies the SVM parameters on each training iteration to find a local optimum that produces the best results. We set the number of iterations for our estimator at 1000. As demonstrated below, our developed classifier scored an accuracy of 82% on the test data set.
# Training Support Vector Machines - SVM and calculating its performance
from sklearn.metrics import classification_report
import numpy as np
from sklearn.pipeline import Pipeline
from sklearn.linear_model import SGDClassifier
text_clf_svm = Pipeline([('vect', CountVectorizer()), ('tfidf', TfidfTransformer()),
('clf-svm', SGDClassifier(loss='hinge', penalty='elasticnet',alpha=1e-3, max_iter=1000, random_state=42))])
text_clf_svm = text_clf_svm.fit(review_comments, classifications)
predicted_svm = text_clf_svm.predict(comment_test)
print(classification_report(classification_test, predicted_svm))
Output
precision recall f1-score support
1
0.83 0.83 0.83 71
10
0.91 0.83 0.87 24
11
0.88 0.70 0.78 20
12
0.70 0.93 0.80 15
13
0.76 0.93 0.84 108
2
0.75 0.75 0.75 16
3
0.91 0.86 0.89 36
4
0.85 0.82 0.84 28
5
0.86 0.74 0.79 34
6
0.89 0.94 0.92 18
7
1.00 0.25 0.40 4
8
1.00 0.37 0.54 19
9
0.86 0.86 0.86 7
avg / total 0.84 0.82 0.82 400
An f1-score of 82% doesn’t seem reliable enough for the purpose of classifying GitHub review comments. I realized that the incorporation of the tf-idf statistic, while useful in other text classification activities, is not the best choice for the classification of review comments.
The reason for this can be traced to the treatment of uncommon words in this technique. In a regular document, an uncommon word, like “abject” for example, would be valuable in classifying that document. Review comments also contain uncommon terms; however, these terms mostly reference source code entities which we would not want to our classifier to place a major importance on.
If our labeled data set for example consisted of a review comment that read, “The Foo class has some formatting issues.”, we would manually assign the Readability classification to this comment. The problem is because Foo is an uncommon term, our tf-idf based SVM classifier would highly correlate this term with the Readability category, which is not what we want as any future review comments containing the term Foo would be given the Readability classification with a very high probability.
A solution to this problem would be to replace any source code entities referenced in review comments by a static string, like <SYMBOL> for example; However, this would be difficult to detect accurately. Therefore, we will simply revert the use of the tf-idf statistic, which raises the f1-score of our classifier significantly to 94%
# Training Support Vector Machines - SVM and calculating its performance
import numpy as np
from sklearn.pipeline import Pipeline
from sklearn.linear_model import SGDClassifier
text_clf_svm = Pipeline([('vect', CountVectorizer()),
('clf-svm', SGDClassifier(loss='hinge', penalty='elasticnet',alpha=1e-3, max_iter=1000, random_state=42))])
text_clf_svm = text_clf_svm.fit(review_comments, classifications)
predicted_svm = text_clf_svm.predict(comment_test)
print(classification_report(classification_test, predicted_svm))
Output
precision recall f1-score support
1
0.94 0.94 0.94 71
10
1.00 0.92 0.96 24
11
1.00 0.95 0.97 20
12
1.00 0.93 0.97 15
13
0.88 0.98 0.93 108
2
0.94 1.00 0.97 16
3
0.97 1.00 0.99 36
4
0.96 0.93 0.95 28
5
1.00 0.91 0.95 34
6
1.00 0.94 0.97 18
7
1.00 0.75 0.86 4
8
1.00 0.74 0.85 19
9
1.00 1.00 1.00 7
avg / total 0.95 0.94 0.94 400
Classifying GitHub Review Comments
We will now leverage the classifier we created in the previous section to classify over 30000 GitHub review comments from the top 100 most forked Java repositories on GitHub. GitHub exposes a REST API that allows developers to interact with the platform, which we will use to mine our Review Comments.
import urllib.request
import json
# URL to consume GitHub REST API to retrieve the top 50 most forked repositories on GitHub
url = 'https://api.github.com/search/repositories?q=language:java&sort=forks&order=desc&per_page=100&page=1'
# Execute the HTTP GET request
resp_text = urllib.request.urlopen(urllib.request.Request(url)).read().decode('UTF-8')
# load the JSON response in a python object
repos_json_obj = json.loads(resp_text)
Next, we’re going to use the GitHub REST API again to collect a list of all the review comments from each repository. Note, the code below will require you to add your own GitHub OAuth token if you wish to execute it yourself.
##########################################
github_access_token = '<GITHUB OAUTH TOKEN>'
##########################################
review_comments = []
# loop through our list of 100 most forked java repositories..
for repo in repos_json_obj['items']:
# i is the current page number
for j in range(1, 11):
# URL to consume GitHub REST API to retrieve 100 review comments
url = 'https://api.github.com/repos/' + repo['owner']['login'] \
+ '/' + repo['name'] + '/pulls/comments?direction=desc&per_page=100&page=' + str(j) \
+ '&access_token=' + github_access_token
# Execute the HTTP GET request and store response in object
json_obj = json.loads(urllib
.request
.urlopen(urllib.request.Request(url))
.read()
.decode('UTF-8'))
# Store all review comments from the response
review_comments.extend(json_obj)
print ('Collected', str(len(review_comments)), 'review comments.')
Collected 32512 review comments.
Next we’ll categorize each review comment using our SVM classifier, and generate a donut chart demonstrating our results.
import matplotlib.pyplot as plt
import matplotlib
from palettable.tableau import Tableau_10
matplotlib.rcParams.update({'font.size': 18})
# Data to plot
labels = ['Readability', 'Naming', 'Documentation', 'Error/Resource Handling',
'Control Structures/Code Flow', 'Visiblity', 'Efficiency', 'Code Organization/Refactoring',
'Concurrency', 'Method Design/Semantics', 'Class Design/Semantics', 'Testing', 'Other']
sizes = [0] * 13
explode = [0.03] * 13
# loop through review comments and score
for review_comment in review_comments:
label = int(text_clf_svm.predict([formatComment(review_comment['body'])])[0])
sizes[label - 1] += 1
# Create a circle for the center of the plot
my_circle=plt.Circle( (0,0), 0.75, color='white')
# Plot
plt.pie(sizes, labels=labels, colors=Tableau_10.hex_colors,
autopct='%1.0f%%', explode=explode, shadow=True, startangle=140)
fig = plt.gcf().set_size_inches(20,20)
plt.gca().add_artist(my_circle)
plt.show()
GitHub Review Comment Classifications
Discussion
Many of the classifications are related to each other at a conceptual level. For example, a Readability problem may be caused due to poor use of Control Structures. Therefore, it is important to note that the classifications were based only on what the review comments explicitly discussed.
That is to say, if a comment read, “poor readability here”, we would expect it to be classified as Readability. However, if the comment read, “This for loop should be moved before line 2”, then Control Structures would be its expected classification, despite readability being the motivating factor for the review suggestion. As mentioned previously, in cases where multiple classifications applied, the comment was classified to a category it spent the most words discussing.
Interestingly, 15% of review comments were found to discuss Readability. This category of comments not only deals with formatting, project conventions and style, but also with how easy the code is to follow for a human.
While existing static analysis tools are effective in dealing with the former area, they lack the ability to check code effectively in the latter domain. This is supported by the fact that over 50% of the repositories included in our study had some form of static analysis tools checking their code. Additionally, a manual survey of 100 randomly sampled comments classified with Readability pointed towards this idea as well. One such comment from my study is illustrated below. While the approach taken by the code contributor is correct, the code review has suggested an alternate approach that increases the clarity of the code.
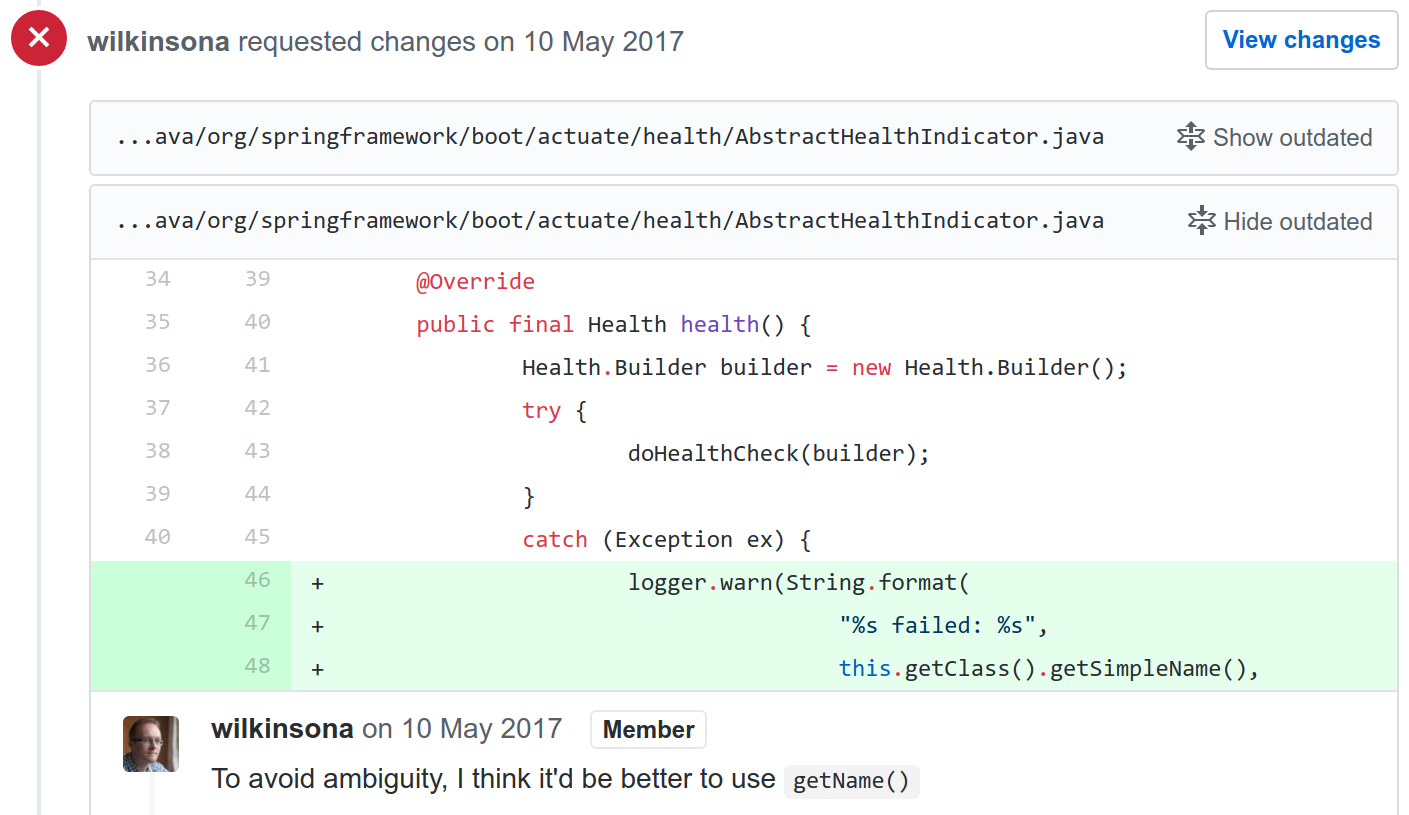
Error handling, class and method design were areas according to which a significant percentage of review comments were classified under. This does not come as a surprise, as these topics vary greatly in the way they are handled from program to program. Moreover, there is often no single correct way to go about their implementation, resulting in an increased amount of developer discussion, and thus review comments, that exist around them.
The most surprising finding from this study is the fact that 44% of review comments were classified according to the Other category. This highlights a major limitation of our approach in using review comments alone to understand the subject of typical code review discussions.
Without the ability to extract meaningful information from the source code alongside the review comment, it is very difficult to understand what the comment alone is discussing.
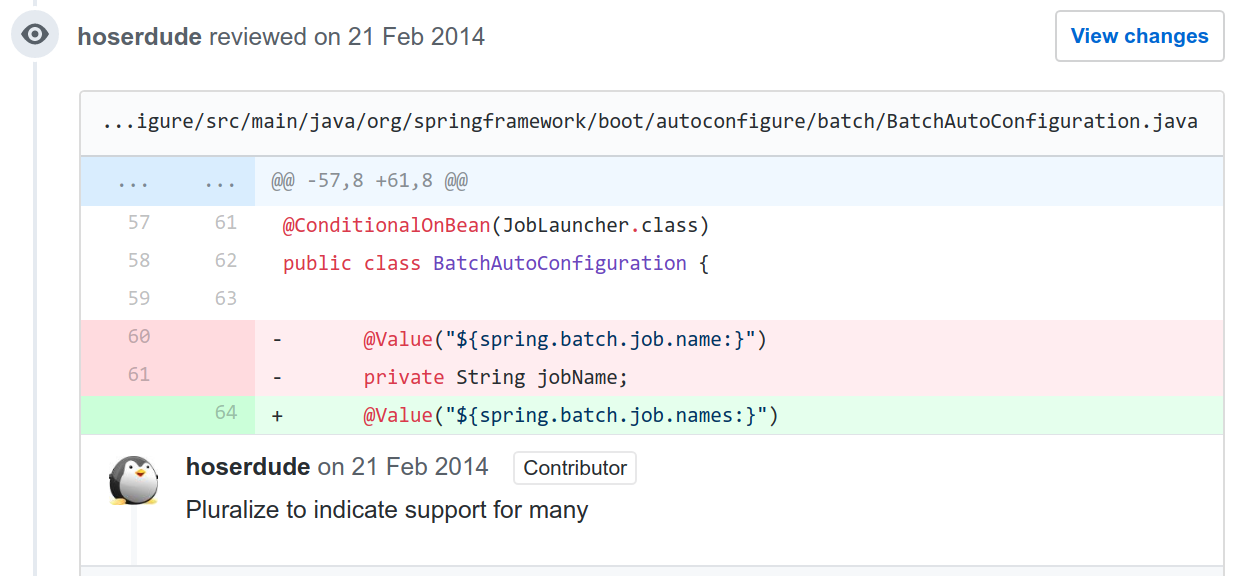
For example, the figure below illustrates a review comment targeted at a Java annotation for a field variable. However, without viewing the source code, it equally possible to suggest that the review comment is targeted at a method name, class name, or even source code documentation.
Many review comments also contain references to source code entities. Without being able to reference them to the source code, their classification becomes a difficult task . Lastly, many review comments consisted of comments serving as a response to a previous comment, which do not always reveal information about the original subject of the discussion.
Closing
This wraps up our experiment on classifying GitHub code review comments! Unfortunately, this experiment only sampled the top 100 most forked Java repositories on GitHub, I wonder how the results would change for different programming languages. If you do end up researching this, please share your results with me!
Did these results match what you had in mind based on your experience doing code reviews? Let me know in the comments below.
