All monoliths are not created equal. Even with the best solution architects, developers, and financial resources available, a legacy application’s microservices transformation journey will be a nightmare if the code is not object-oriented.
Wanting to benefit from scalability and cost-efficiency of cloud technologies, organizations are increasingly migrating their monolithic applications to microservices and serverless based architectures. Due to the nature of typical monoliths however, this migration is often a long and difficult process.

The reason? The most time consuming aspect of the migration journey involves decoupling the monolith into smaller, more refined services while ensuring that these new components have desirable properties of a distributed system (autonomy, scalability, and so on).
And this decoupling process will be much more frustrating and tedious than necessary if the code does not have certain characteristics that make it easy to split up and compose into smaller and more focussed components. In this article I’ll demonstrate how four key Object Oriented Programming principles accelerate this process.
By the end, I’m hopefull that you’ll seriously consider writing high quality Object Oriented code when starting your next greenfield project so that you can avoid many of the difficulties typically associated with microservices adoption down the road.
Do One Thing Well
Classes that take on many responsibilities or contain a lot of data, also known as God Classes, are very difficult to read, maintain, and extend due to their enormous size. For this reason, classes in an Object Oriented design should focus on doing one thing well, and behave as a logically single, atomic unit. If the complexity of an object exceeds a reasonable level, it should be refactored into two or more separate entities.

When we consider that each service in a microservices architecture should focus on a specific domain, this method of designing classes gives us a great deal of flexibility in determining how we want to decouple a monolithic application into such services.
As an example, consider a scenario where a code base consists of many God classes. Clearly, your ability to decouple the application into services that focus on specific domains is severely limited because the basic building blocks of these services (i.e the objects themselves), are extremely broad and unfocused. In such scenarios, you’ll have to refactor those large classes into smaller components that have fewer responsibilities before you can compose them into microservices with the desired level granularity.
Message Passing
Perhaps the most misunderstood aspect of Object Oriented systems is inter-object communication. In fact, a method call was not the way modules in an Object Oriented system were intended to communicate, rather it was through messaging.
Communication in OOP should be thought as message passing, not method calls. Message passing results in smart objects that accomplish tasks together via content negotiation. Method calls result in many unintelligent objects that are constantly told how to do their job. #oop
— Muntazir Fadhel (@FadhelMuntazir) March 5, 2019
The difference between them is in the way we perceive method calls versus messages. Calling a method essentially puts the person making the method call in control of running the process. The caller gets the callee to do something and prevents it from doing something that the caller does not want. Message passing on the other hand revolves around negotiation, and this is the key in building object-oriented systems.
 Method calling vs content negotiation via message passing
Method calling vs content negotiation via message passing
A major challenge in converting a monolith into microservices based architecture lies in re-designing its communication mechanism. Microservices are ideally integrated using asynchronous communication to enforce microservice autonomy and to develop an architecture that is resilient when microservices fail or underperform.
The problem arises when code is written in a procedural and imperative way. Breaking up a monolith that consists of such code into microservices will force architects to implicitly use a synchronous communication pattern right from the onset when that might not be the most optimal solution.
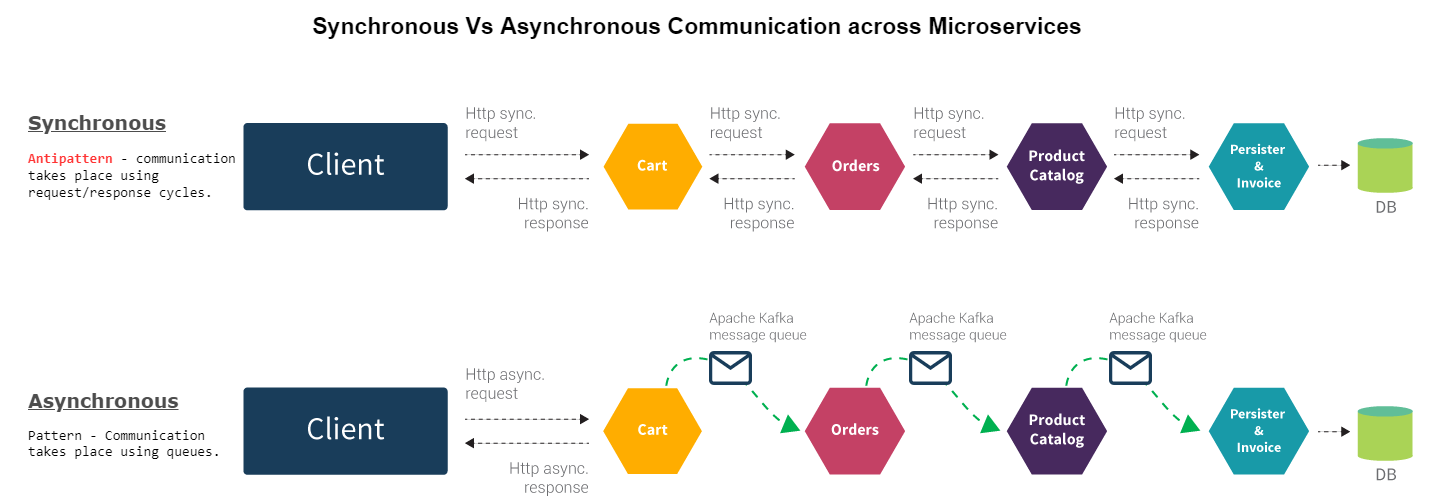
On the other hand, code that practices message passing facilitates the decoupling of a monolith into microservices that communicate using asynchronous patterns to a great degree. A module that practices message passing properly does not require any response from the client in other for it to continue doing it’s job. It does not control it’s clients, and assumes that any client modules receiving it’s messages are smart enough to do whatever needs to be done next. The final result of composing such objects into microservices is an architecture that can be adapted to use asynchronous communication mechanisms with little effort.
Coupling
Coupling represents the degree to which a module or object is independent from others. A highly Coupled module relies on and modifies the states and internals of other objects to do its job, whereas a loosely Coupled module relies on a minimal set of interfaces belonging to other objects to do its job.
Object Oriented systems generally avoid highly Coupled modules since they are increasingly difficult to maintain and test as more components are introduced into the system. Unsurprisingly, distributed cloud architectures also favour the design of services and components that do not rely on many other components to do its job. In this case however, the motivating goal is to support component evolution.
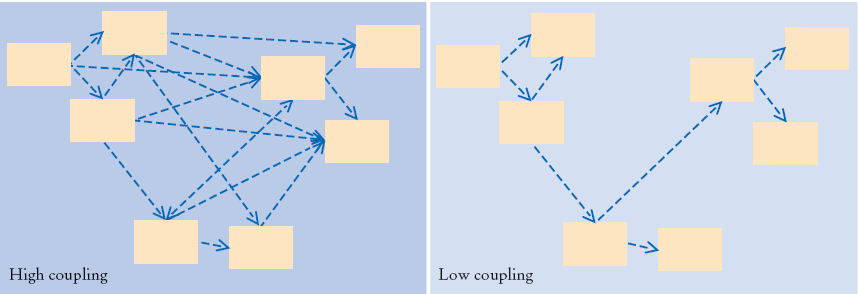
That is to say, components in a distributed architecture should have the ability to be changed, upgraded, or replaced independently without affecting the functioning of other components. This requires microservices to be designed in a way that makes them primarily responsible for running their own show. In return, teams responsible for different services will have the autonomy to make decisions and act independently from each other.
With that said, you can only decouple your monolith into services that maintain their autonomy to the degree of autonomy the individual objects composing those services have, which comes down to Coupling. Therefore, loosely coupled code will lend itself to autonomous services, while highly coupled code will need a a lot of refactoring before it can achieve this goal.
Information Hiding
Information Hiding refers to the process of writing modules in a way that keeps their details relating to core design decisions, especially those that are expected to change, hidden from other objects. As a result, callers of an object are effectively decoupled from it’s internal workings, which makes it possible for the ‘hidden’ parts to change without needing to change the way the object is called.

This principle is also a desirable property for components in micoservices/serverless based architecture. A microservice for example, should be designed as a black box in which its internal complexity and details are hidden from other services in the system. Because of this, communication between services can now take place via well defined APIs, which is a desirable trait of microservice architectures.
It should be easy to see now why the process of decoupling a monolith that practices Information Hiding into microservices that behave as black boxes is a straight forward task. Simply put, each class that practices Information Hiding already behaves as a mini black box of sorts, which makes composing them into larger microservices that behave as black boxes a trivial exercise.
On the other hand, if Information Hiding is not properly observed in the original code, you are at risk of decoupling the monolith into microservices that depend on the internal workings of other microservices to provide their service. Obviously, this will hurt the maintainability and evolution of the overall architecture.
In Closing
The functioning and design of an ideal microservice shares many characteristics with the functioning and design of an ideal object in an object-oriented system. For this reason, any process of migrating a monolithic application to a microservices-like architecture will be greatly simplified if the application exhibits good object-oriented practices in the first place.
