
Easily Migrate Postgres/MySQL Records to InfluxDB
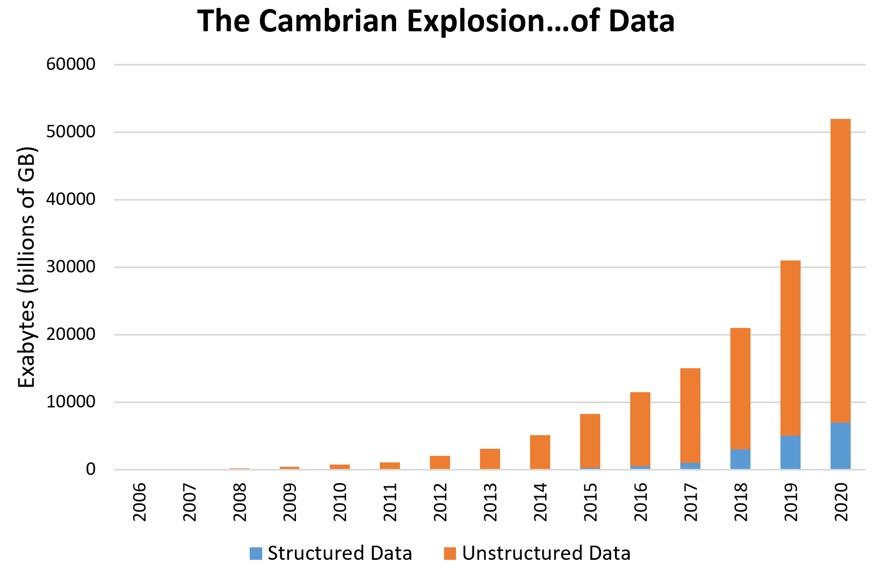
Computers have been collecting and storing data in relational/schema systems for many years. However, digital storage growth outpaces that of computing processing power by leaps and bounds. Additionally, the amount of unstructured that is collected greatly exceeds that of structured data, further limiting the utility of tradional database systems. For these reasons, today’s data storage technqiues call for some new technical constructs required to break the boundaries of traditional transaction-processing databases.
Time Series Databases
In an effort to garner meaning from rapidly growing data sources, an increasing amount of organizations find themselves having to move their data from a traditional relational database like PostgreSQL or MySQL to a non-relational database like MongoDB, or in some cases, a Time Series Database (TSDB). The scenario under consideration for this article is based on the need to analyze and visualize trends over large periods of time over large amounts of time series data. There are a few reasons as to why typical relational databases are inefficient for storing time series data. First, at every measurement interval, tables are populated with fresh data that increases table cardinality. The consequence is that table cardinality as well the space taken on disk increases with the number of measurements. As soon as table indexes become large enough to prevent themselves to be cached, data retrieval becomes significantly slow thus jeopardizing the performance of applications sitting on top ofthe database. Therefore, a TSDB is much more attractive solution for the anaysis and storage of time series data for two main reasons:
Efficiency
A TSDB co-locates chucks of data within the same time range on the same physical section of the database cluster and hence enables quick access for faster, more efficient analysis. As a result, range queries, even over many records complete extremely quickly. In many cases, regular databases produce an index out of memory error because of the sheer volume of time series dataand subsequently affect the performance of read and write operations.
Usability
TSDBs typically include functions and operations that are common to time series data analysis. First, they utilize data retention policies, continuous queries, flexible time aggregations,and range queries. Additionally, they offer mathematical querying functionality that allows users to understand their data in ways common to the analysis of time series data. As a result, the overall user experience in dealing with time series data is significantly improved in comparison to database systems in which this functionality needs to be manually configured and developed.
Python Script to Migrate SQL Data to InfluxDB
The following script transfers records from a PostgreSQL or MySQL database to InfluxDB - just fill out the relevant database connection information and schema design object as required. You need to also make sure you have the appropriate python libraries installed: pip install psycopg2 mysqlclient indfluxdb. Note, InfluxDB incorporates some key concepts that might seem unfamiliar for those coming from a typical relation database background. These should be reviewed and understood before using the script below.
### MySQL DB info ###
#import MySQLdb
#conn = MySQLdb.connect(host="localhost", # your host, usually localhost
# user="john", # your username
# passwd="megajonhy", # your password
# db="jonhydb") # name of the data base
### PostgreSQL DB info ###
import psycopg2
import psycopg2.extras
postgresql_table_name = ""
conn = psycopg2.connect("dbname=<DB_NAME> user=<USER_NAME>" +
"password=<USER_PASSWORD> host=<POSTGRESQL_HOST>")
### InfluxDB info ####
from influxdb import InfluxDBClient
influx_db_name = ""
influxClient = InfluxDBClient("<INFLUX_HOST>", "<INFLUX_PORT>")
influxClient.delete_database(influx_db_name)
influxClient.create_database(influx_db_name)
# dictates how columns will be mapped to key/fields in InfluxDB
schema = {
"time_column": "", # the column that will be used as the time stamp in influx
"columns_to_fields" : ["",...], # columns that will map to fields
"columns_to_tags" : ["",...], # columns that will map to tags
"table_name_to_measurement" : "", # table name that will be mapped to measurement
}
'''
Generates an collection of influxdb points from the given SQL records
'''
def generate_influx_points(records):
influx_points = []
for record in records:
tags = {}, fields = {}
for tag_label in schema['columns_to_tags']:
tags[tag_label] = record[tag_label]
for field_label in schema['columns_to_fields']:
fields[field_label] = record[field_label]
influx_points.append({
"measurement": schema['table_name_to_measurement'],
"tags": tags,
"time": record[schema['time_column']],
"fields": fields
})
return influx_points
# query relational DB for all records
curr = conn.cursor('cursor', cursor_factory=psycopg2.extras.RealDictCursor)
# curr = conn.cursor(dictionary=True)
curr.execute("SELECT * FROM " + schema['table_name_to_measurement'] + "ORDER BY " + schema['column_to_time'] + " DESC;")
row_count = 0
# process 1000 records at a time
while True:
print("Processing row #" + (row_count + 1))
selected_rows = curr.fetchmany(1000)
influxClient.write_points(generate_influx_points(selected_rows))
row_count += 1000
if len(selected_rows) < 1000:
break
conn.close()