Elasticsearch is an open-source, broadly-distributable, readily-scalable, enterprise-grade search engine. Accessible through an extensive and elaborate API, Elasticsearch can power extremely fast searches that support your data discovery applications. I recently worked on implementing a multi-language search engine using Elastic Search and found that for certain use cases, rolling Elastic Search for your back end offers significant advantages over conventional SQL database systems.

Dealing With Human Languages
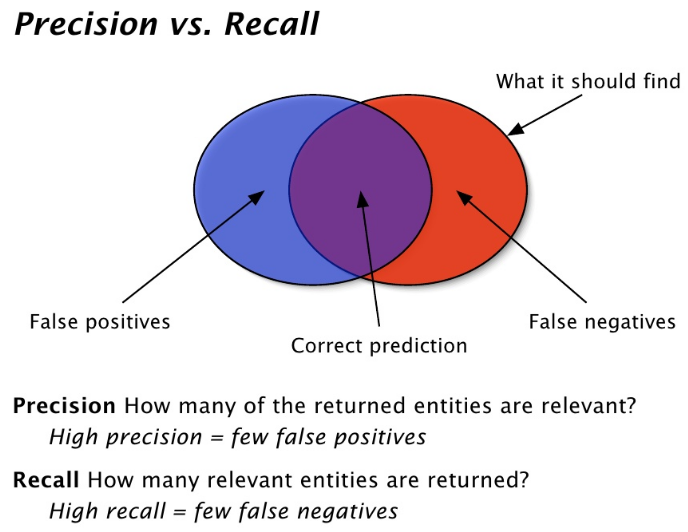
Full-text search is a battle between precision — returning as few irrelevant documents as possible, and recall—returning as many relevant documents as possible. When dealing with documents that contain searchable text in both Arabic and English, as was the case for the engine I needed to build, the problem becomes even more complex. Outlined below are some of the challenges I faced while developing a search engine and how Elastic Search provided effective solutions for them.
Synonym Filters
A user searching for “intelligent” would expect not only to find documents containing the word “intelligent”, but documents containing words that have a similar meaning to “intelligent” as well (“wise”, “smart”, …). While results for these secondary words should have lower priority, they should still show up at some point down the list. Furthermore, its not always as simple as finding synonyms of the given search terms - sometimes, we need to relate terms that are not synonyms of each other. For example, a user searching for “United States” might expect to see results for “USA”, “America” and the “United States of America” as well. This is where Elastic Search synonym filters come into play.
Synonyms help to broaden the scope of the user’s search by relating concepts and ideas. We can use Elastic Search synonym filters to make a word more generic. This allows the search to account for retrieving documents containing closely related words/ideas. For example, I can define a simple rule for my synonym filter in the following way:
jump → jump,leap,hop
intelligent → wise,knowledgeable,smart
Once this rule is implemented, a search for intelligent will retrieve
documents containing “wise”, “knowledgeable” and “smart” as well. Instructions
for setting up synonyms can be found here.
Word Stemming
Most languages of the world are inflected, meaning that words can change their form to express differences in number, tense, gender, person, cause and mood.

While inflection aids expressivity, it interferes with retrievability, as a single root word sense (or meaning) may be represented by different sequences of letters. For example, a user searching for “run” would miss out on possibly relevant documents containing “runner” or “running”. Stemming filters attempt to improve recall by reducing each word in a document to its root form before carrying out the query. This is not always a good thing, as a user may be soley interested in documents containing the word “run” but would see results for “running” and “runner” in this case; therefore, using a Bool Query to combine the results of the un-stemmed, boosted query with the stemmed query gives the best of both worlds. Multiple Algorithmic and Dictionary Stemmers are provided by Elastic Search right out of the box.
Fuzzy Searching
How do we account for the fact that users of our search engine will possibly use one of the American or British spellings of any given word (color vs colour)? We certainly don’t want to have to define synonyms in this case; instead, we can take advantage of Elastic Search Fuzzy Queries. Fuzzy matching treats two words that are “fuzzily” similar as if they were the same word. Here, fuzziness, based on the Levenshtein distance, describes the number of single-character edits required to transform one word into the other.
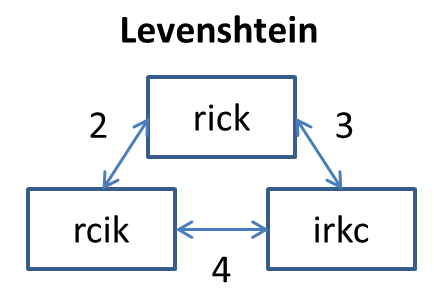
Not only does this type of query allow us to account for minor variations in the spelling of translated words, but fuzzy searching allows us to return relevant results for misspelled words and for words that contain typos as well!
Simplified User Search Experience
Elasticsearch is a document oriented database and does not require you to specify a schema upfront. Throw a JSON-document at it, and it will do some educated guessing to infer its type. This saves a great deal amount of time in data retrieval, and Elastic Search will also take care of storing your documents such that they are optimized for search and retrieval. You can now take advantage of the various queries provided by Elastic Search for analyzing and querying your data. Because I was designing a search engine open to the public, I wanted to ensure that both technical oriented and non-technical oriented users could get the most out of the search. The Query String Query is the perfect query for this task. Its supports both simple and complex queries, for example, the query:
Strawberry Cuppy Cakes
Would return all documents containing one or more of the terms “Strawberry”, “Cuppy” or “Cakes”.
At the same time however, more advanced users can take advantage of Lucene’s Query Parser Syntax in order to gain deeper insights from the data:
(title:"foo bar" AND body:"quick fox") OR title:fox
This would search for either the phrase “foo bar” in the title field AND the phrase “quick fox” in the body field, or the word “fox” in the title field. The main point here is that queries of varying levels of complexity can all be expressed through a single, flexible searching mechanism.
Summary
In this article, I have shown how Elastic Search ships with some pretty awesome tools for creating a great search engine. Hopefully, you’ve learned something that will help you decide on whether or not to use Elastic Search for your next project.
